stable_diffusion
@stable_diffusion@lemmy.dbzer0.com
This is a remote community, information on this page may be incomplete. View at Source ↗
Discuss matters related to our favourite AI Art generation technology
Also see
- Stable Diffusion Art (See its sidebar for more GenAI Art comms)
- !aihorde@lemmy.dbzer0.com
Other communities
- !auai@programming.dev
- !ArtificialIntelligence@kbin.social
- Submitted 6 months ago by lefthandeddude@lemmy.dbzer0.com | 15 comments
- Submitted 6 months ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 6 months ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 2 years ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 1 year ago by comfy@lemmy.ml | 2 comments
- Submitted 1 year ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 1 year ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 6 months ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 6 months ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 6 months ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 6 months ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- RichardAragon/NightshadeAntidote: An 'antidote' to the recently released AI poison pill project known as Nightshade.github.com ↗Submitted 2 years ago by Even_Adder@lemmy.dbzer0.com | 15 comments
- Submitted 2 years ago by Even_Adder@lemmy.dbzer0.com | 1 comment
- wouterverweirder/comfyui_live_input_stream: Real-time video input nodes for ComfyUI that enable webcam capture, screen sharing, and MJPEG stream processing with live preview and cropping capabilities.github.com ↗Submitted 6 months ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 6 months ago by Even_Adder@lemmy.dbzer0.com | 4 comments
- Submitted 2 years ago by Even_Adder@lemmy.dbzer0.com | 4 comments
- Submitted 1 year ago by Even_Adder@lemmy.dbzer0.com | 2 comments
- Submitted 2 years ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 2 years ago by Even_Adder@lemmy.dbzer0.com | 5 comments
- Submitted 1 year ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 2 years ago by Even_Adder@lemmy.dbzer0.com | 1 comment
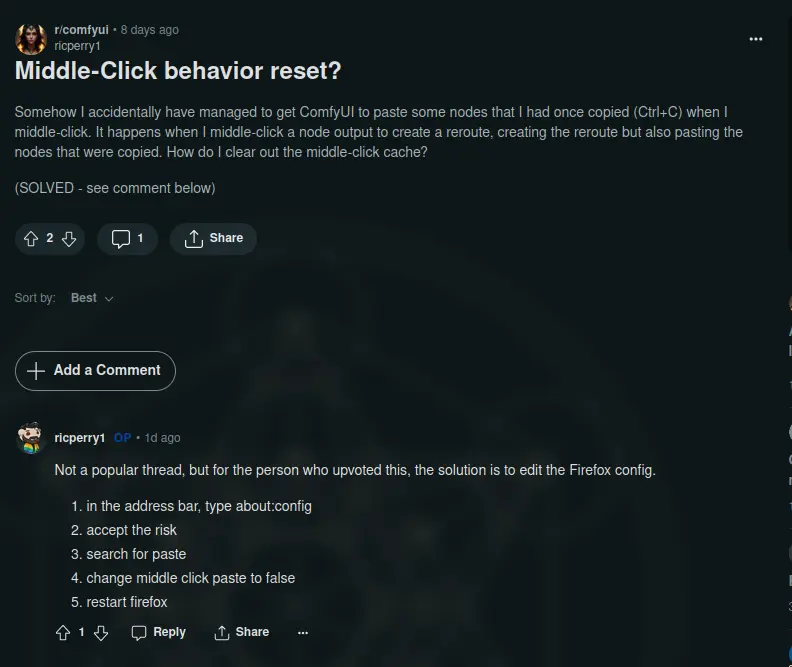
- ricperry1, when you find your way here and read this, thank you for your consideration. You helped at least more then 1 other person this week.sopuli.xyz ↗Submitted 2 years ago by webghost0101@sopuli.xyz | 1 comment
- Submitted 2 years ago by Even_Adder@lemmy.dbzer0.com | 1 comment
- Submitted 6 months ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 2 years ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 7 months ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 7 months ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 7 months ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 1 year ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- lllyasviel/Stable Diffusion WebUI Forge for Low VRAM machines huge VRAM and Speed Improvementsgithub.com ↗Submitted 2 years ago by Even_Adder@lemmy.dbzer0.com | 1 comment
{kind=link}
{kind=link}
{kind=link}
{kind=link}