Comment on OpenAI Insider Estimates 70 Percent Chance That AI Will Destroy or Catastrophically Harm Humanity
lvxferre@mander.xyz 2 years agoI also apologise for the tone. That was a knee-jerk reaction from my part; my bad.
(In my own defence, I’ve been discussing this topic with tech bros, and they rather consistently invert the burden of the proof. Often to evoke Brandolini’s Law. You probably know which “types” I’m talking about.)
On-topic. Given that “smart” is still an internal attribute of the blackbox, perhaps we could gauge better if those models are likely to become an existential threat by 1) what they output now, 2) what they might output in the future, and 3) what we [people] might do with it.
It’s also easier to work with your example productively this way. Here’s a counterpoint:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
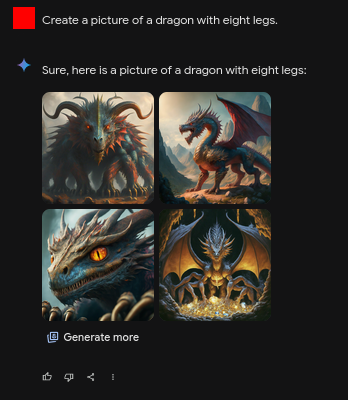
The prompt asks for eight legs, and only one pic was able to output it correctly; two ignored it, and one of the pics shows ten legs. That’s 25% accuracy.
I believe that the key difference between “your” unicorn and “my” eight-legged dragon is in the training data. Unicorns are fictitious but common in popular culture, so there are lots of unicorn pictures to feed the model with; while eight-legged dragons are something that I made up, so there’s no direct reference, even if you could logically combine other references (as a spider + a dragon).
So their output is strongly limited by the training data, and it doesn’t seem to follow some strong logic. What they might output in the future depends on what we add in; the potential for decision taking is rather weak, as they wouldn’t be able to deal with unpredictable situations. And thus their ability to go rogue.
[Note: I repeated the test with a horse instead of a dragon, within the same chat. The output was slightly less bad, confirming my hypothesis - because pics of eight-legged horses exist due to the Sleipnir.]
Neural nets
Neural networks are a different can of worms for me, as I think that they’ll outlive LLMs by a huge margin, even if the current LLMs use them. However, how they’ll be used is likely considerably different.
For example, current state-of-art LLMs are coded with some “semantic” supplementation near the embedding, added almost like an afterthought. However, semantics should play a central role in the design of the transformer - because what matters is not the word itself, but what it conveys.
That would be considerably closer to a general intelligence than to modern LLMs - because you’re effectively demoting language processing to input/output, that might as well be subbed with something else, like pictures. In this situation I believe that the output would be far more accurate, and it could theoretically handle novel situations better. Then we could have some concerns about AI being an existential threat - because people would use this AI for decision taking, and it might output decisions that go terribly right, as in that “paperclip factory” thought experiment.
The fact that we don’t see developments in this direction yet shows, for me, that it’s easier said than done, and we’re really far from that.
CanadaPlus@lemmy.sdf.org 2 years ago
To be clear, I wasn’t talking about an actual picture generating model. It was raw GPT trained on just text, asked to write instructions for a paint program to output a unicorn. That’s more convincing because it’s multiple steps away from the basic task it was trained on. Here, I found the paper, it starts with unicorns and then starts exploring other images, and eventually they delve into way more detail than I actually read. There’s a video talk that goes with it.
The trick with trying to “make” an AI do semantics, is that we don’t know what semantics is, exactly. I mean, that’s kind of what we started out with (remember the old pattern-matching chatbots?) but simpler approaches often worked better. Even the Transformer block itself is barely more complicated than a plain feed-forward network. I don’t think that’s so much because neural nets are more efficient (they really aren’t) but because we were looking for an answer to a question we didn’t have.
I think the challenge going forwards is freeing all that know-how from the black box we’ve put it in, somehow. Assuming we do want to mess with something so dangerous if handled carelessly.