Abstract
As online shopping is growing, the ability for buyers to virtually visualize products in their settings—a phenomenon we define as “Virtual Try-All”—has become crucial. Recent diffusion models inherently contain a world model, rendering them suitable for this task within an inpainting context. However, traditional image-conditioned diffusion models often fail to capture the fine-grained details of products. In contrast, personalization-driven models such as DreamPaint are good at preserving the item’s details but they are not optimized for real-time applications.
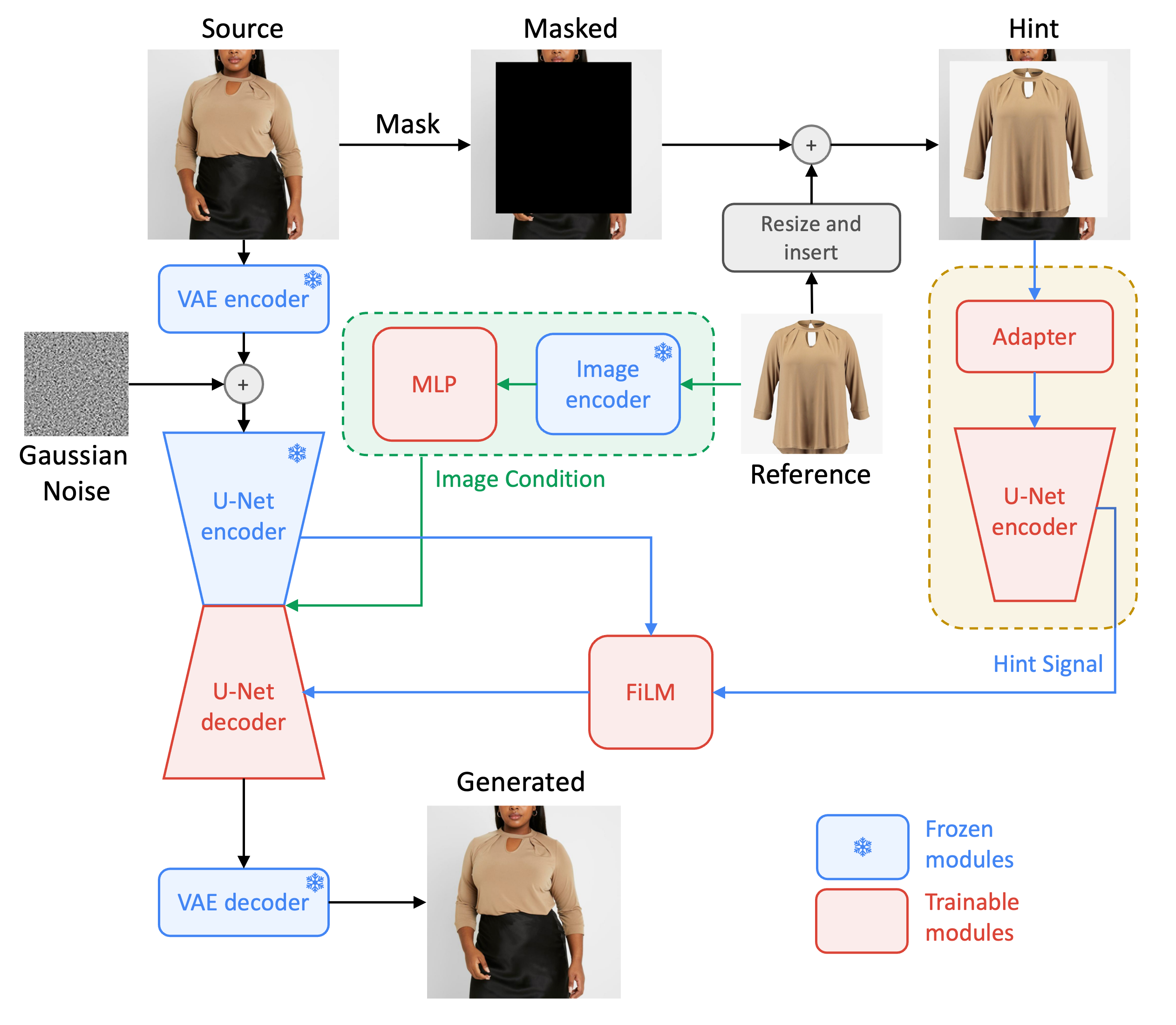
We present Diffuse to Choose, a novel diffusion-based image-conditioned inpainting model that efficiently balances fast inference with the retention of high-fidelity details in a given reference item while ensuring accurate semantic manipulations in the given scene content. Our approach is based on incorporating fine-grained features from the reference image directly into the latent feature maps of the main diffusion model, alongside with a perceptual loss to further preserve the reference item’s details. We conducted extensive testing on both in-house and publicly available datasets, and showed that Diffuse to Choose is superior to existing zero-shot diffusion inpainting methods as well as few-shot diffusion personalization algorithms like DreamPaint.
Paper: arxiv.org/abs/2401.13795
Code: (coming soon)
Project Page: diffuse2choose.github.io
{kind=link}
{kind=link}
{kind=link}
tagginator@utter.online [bot] 2 years ago
New Lemmy Post: Diffuse to Choose: Enriching Image Conditioned Inpainting in Latent Diffusion Models for Virtual Try-All (https://lemmy.dbzer0.com/post/13154806)
Tagging: #StableDiffusion
(Replying in the OP of this thread (NOT THIS BOT!) will appear as a comment in the lemmy discussion.)
I am a FOSS bot. Check my README: https://github.com/db0/lemmy-tagginator/blob/main/README.md