{kind=link}
This post is a developer diary , kind of. I’m making an improved CLIP interrogator using nearest-neighbor decoding.
It doesn’t require GPU to run, and is super quick. The reason for this is that the text_encodings are calculated ahead of time
, unlike the Pharmapsychotic model aka the “vanilla” CLIP interrogator : huggingface.co/spaces/…/discussions
//----//
This post gonna be a bit haphazard, but that’s the way things are before I get the huggingface gradio module up and running.
Then it can be a fancy “feature” post , but no clue when I will be able to code that.
So better to give an update on the ad-hoc solution I have now.
The NND method I’m using is described here , in this paper which presents various ways to improve CLIP Interrogators: arxiv.org/pdf/2303.03032
{kind=link}
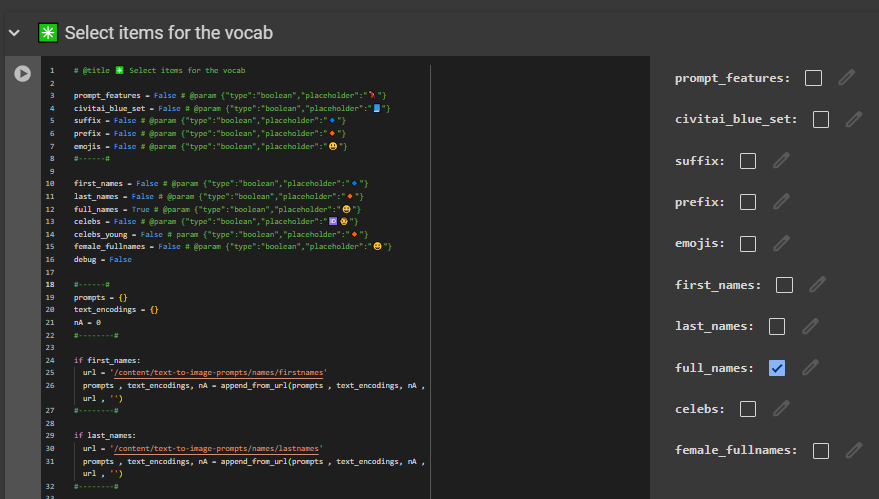
Easier to just use the notebook then follow this gibberish. We pre-encode a bunch of prompt items , then select the most similiar one using dot product. Thats the TLDR.
Right now the resources available are the ones you see in the image.
I’ll try to showcase it at some point. But really , I’m mostly building this tool because it is very convenient for myself + a fun challenge to use CLIP.
It’s more complicated than the regular CLIP interrogator , but we get a whole bunch of items to select from , and can select exactly “how similiar” we want it to be to the target image/text encoding.
The {itemA|itemB|itemC} format is used as this will select an item at random when used on the perchance text-to-image servers, in in which I have a generator where I’m using the full dataset , perchance.org/fusion-ai-image-generator
It takes minutes to load a fraction of the sets from perchance servers before this generator is “up and running” so-to speak.
I plan to migrate the database to a Huggingface repo to solve this.
huggingface.co/datasets/…/text-to-image-prompts
The {itemA|itemB|itemC} format is also a build-in random selection feature on ComfyUI , coincidentally :
{kind=link}
Source : blenderneko.github.io/…/Textprompts/#up-and-down-…
Links/Resources posted here might be useful to someone in the meantime.
{kind=link}
You can find tons of strange modules on the Huggingface page : huggingface.co/spaces
{kind=link}
For now you will have to make do with the NND CLIP Interrogator notebook : huggingface.co/…/sd_token_similarity_calculator.i…
{kind=link}
text_encoding_converter (also in the NND notebook) : huggingface.co/…/indexed_text_encoding_converter.…
I’m using this to batch process JSON files into json + text_encoding paired files. Really useful (for me at least) when building the interrogator. Runs on the either Colab GPU or on Kaggle for added speed: www.kaggle.com
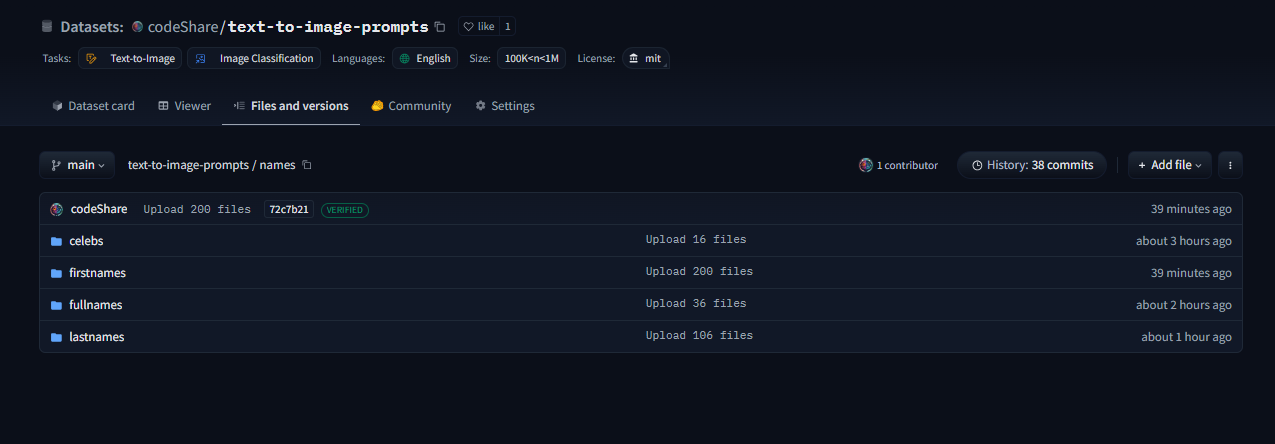
Here is the dataset folder huggingface.co/datasets/…/text-to-image-prompts:
{kind=link}
Inside these folders you can see the auto-generated safetensor + json pairings in the “text” and “text_encodings” folders.
The JSON file(s) of prompt items from which these were processed are in the “raw” folder.
{kind=link}
The text_encodings are stored as safetensors. These all represent 100K female first names , with 1K items in each file.
By splitting the files this way , it uses way less RAM / VRAM as lists of 1K can be processed one at a time.
{kind=link}
//-----//
Had some issues earlier with IDs not matching their embeddings but that should be resolved with this new established method I’m using. The hardest part is always getting the infrastructure in place.
I can process roughly 50K text encodings in about the time it takes to write this post (currently processing a set of 100K female firstnames into text encodings for the NND CLIP interrogator. )
EDIT : Here is the output uploaded huggingface.co/datasets/codeShare/…/firstnames
I’ve updated the notebook to include a similarity search for ~100K female firstnames , 100K lastnames and a randomized 36K mix of female firstnames + lastnames
Sources for firstnames : huggingface.co/datasets/jbrazzy/baby_names
List of most popular names given to people in the US by year
Sources for lastnames : github.com/Debdut/names.io
An international list of all firstnames + lastnames in existance, pretty much . Kinda borked as it is biased towards non-western names. Haven’t been able to filter this by nationality unfortunately.
//------//
Its a JSON + safetensor pairing with 1K items in each. Inside the JSON is the name of the .safetensor files which it corresponds to. This system is super quick :)!
I plan on running a list of celebrities against the randomized list for firstnames + lastnames in order to create a list of fake “celebrities” that only exist in Stable Diffusion latent space.
An “ethical” celebrity list, if you can call it that which have similiar text-encodings to real people but are not actually real names.
I have plans on making the NND image interrogator a public resource on Huggingface later down the line, using these sets. Will likely use the repo for perchance imports as well: huggingface.co/datasets/…/text-to-image-prompts