{kind=link}
Created by me.
Link : huggingface.co/…/sd_token_similarity_calculator.i…
This is how the notebook works:
Similiar vectors = similiar output in the SD 1.5 / SDXL / FLUX model
CLIP converts the prompt text to vectors (“tensors”) , with float32 values usually ranging from -1 to 1
Dimensions are [ 1x768 ] tensors for SD 1.5 , and a [ 1x768 , 1x1024 ] tensor for SDXL and FLUX.
The SD models and FLUX converts these vectors to an image.
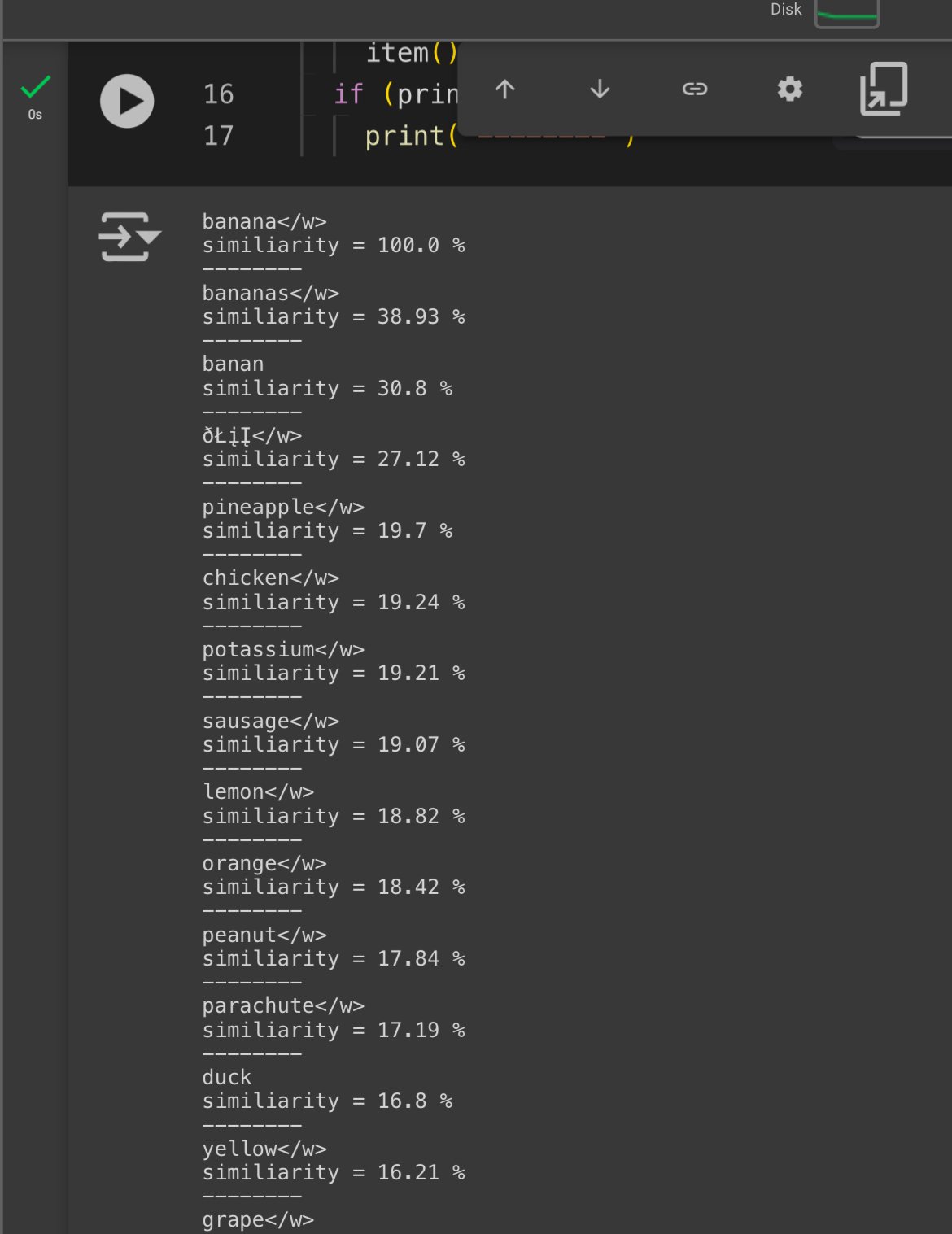
This notebook takes an input string , tokenizes it and matches the first token against the 49407 token vectors in the vocab.json : https://huggingface.co/black-forest-labs/FLUX.1-dev/tree/main/tokenizer
It finds the “most similiar tokens” in the list. Similarity is the theta angle between the token vectors.
{kind=link}
The angle is calculated using cosine similarity , where 1 = 100% similarity (parallell vectors) , and 0 = 0% similarity (perpendicular vectors).
Negative similarity is also possible.
So if you are bored of prompting “girl” and want something similiar you can run this notebook and use the “chick” token at 21.88% similarity , for example
You can also run a mixed search , like “cute+girl”/2 , where for example “kpop” has a 16.71% similarity
Sidenote: If you are wondering about token magnitude, Prompt weights like (banana:1.2) will scale the magnitude of the corresponding 1x768 tensor(s) by 1.2 . So thats how prompt token magnitude works.
Source: https://huggingface.co/docs/diffusers/main/en/using-diffusers/weighted_prompts*
So TLDR; vector direction = “what to generate” , vector magnitude = “prompt weights”
AdComfortable1514@lemmy.world 1 year ago
New stuff
Image
Image
Image
Paper: arxiv.org/abs/2303.03032
Takes only a few seconds to calculate.
Most similiar suffix tokens : “{vfx |cleanup |warcraft |defend |avatar |wall |blu |indigo |dfs |bluetooth |orian |alliance |defence |defenses |defense |guardians |descendants |navis |raid |avengersendgame }”
most similiar prefix tokens : “{imperi-|blue-|bluec-|war-|blau-|veer-|blu-|vau-|bloo-|taun-|kavan-|kair-|storm-|anarch-|purple-|honor-|spartan-|swar-|raun-|andor-}”