stable_diffusion
@stable_diffusion@lemmy.dbzer0.com
This is a remote community, information on this page may be incomplete. View at Source ↗
Discuss matters related to our favourite AI Art generation technology
Also see
- Stable Diffusion Art (See its sidebar for more GenAI Art comms)
- !aihorde@lemmy.dbzer0.com
Other communities
- !auai@programming.dev
- !ArtificialIntelligence@kbin.social
- Submitted 1 year ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 1 year ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 1 year ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 2 years ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- ChangeTheConstants/SeedVarianceEnhancer: A ComfyUI node that adds random noise to text embeddings.github.com ↗Submitted 6 months ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 6 months ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 2 years ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 2 years ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 2 years ago by Even_Adder@lemmy.dbzer0.com | 1 comment
- Submitted 2 years ago by Even_Adder@lemmy.dbzer0.com | 1 comment
- RB-Modulation: Training-Free Personalization of Diffusion Models using Stochastic Optimal Controli.imgur.com ↗Submitted 2 years ago by Even_Adder@lemmy.dbzer0.com | 1 comment
- Submitted 2 years ago by Even_Adder@lemmy.dbzer0.com | 1 comment
- Submitted 1 year ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- New SDXL Controlnet Models for Scribble, Scribble-Anime, Openpose, and Canny Releasedhuggingface.co ↗Submitted 2 years ago by Even_Adder@lemmy.dbzer0.com | 1 comment
- Submitted 1 year ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Ubisoft Open-Sources the CHORD Model and ComfyUI Nodes for End-to-End PBR Material Generationblog.comfy.org ↗Submitted 6 months ago by Even_Adder@lemmy.dbzer0.com | 2 comments
- Kwai-Kolors — a large text-to-image model bilingual in both Chinese and English, and supports a context length of 256 tokens.github.com ↗Submitted 1 year ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 1 year ago by hok@lemmy.dbzer0.com | 1 comment
- v0xie/sd-webui-incantations: An implementation of Perturbed Attention Guidance For A1111github.com ↗Submitted 2 years ago by Even_Adder@lemmy.dbzer0.com | 2 comments
- aquif-ai/aquif-Image-14B · A 14.3B Parameters Text-to-Image Generation Fine-Tuned From Wan 2.2 A14Bhuggingface.co ↗Submitted 6 months ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 6 months ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- GitHub - ifilipis/ComfyUI-DyPE: ComfyUI DyPE, enabling artifact-free 4K+ image generation for Qwen, Flux and Z-Imagegithub.com ↗Submitted 6 months ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 6 months ago by Even_Adder@lemmy.dbzer0.com | 1 comment
- Submitted 1 year ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- GitHub - neuratech-ai/ComfyUI-MultiGPU: Rudimentary Support for Using Multiple GPUs in a ComfyUI Workflowgithub.com ↗Submitted 1 year ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- DialogGen: Multi-modal Interactive Dialogue System for Multi-turn Text-to-Image Generationi.imgur.com ↗Submitted 2 years ago by Even_Adder@lemmy.dbzer0.com | 1 comment
- Submitted 6 months ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- shootthesound/comfyUI-Realtime-Lora: Train LoRAs directly inside ComfyUI for Z-image Turbo, SDXL, Flux, WAN 2.2github.com ↗Submitted 6 months ago by Even_Adder@lemmy.dbzer0.com | 0 comments
- Submitted 6 months ago by Even_Adder@lemmy.dbzer0.com | 0 comments
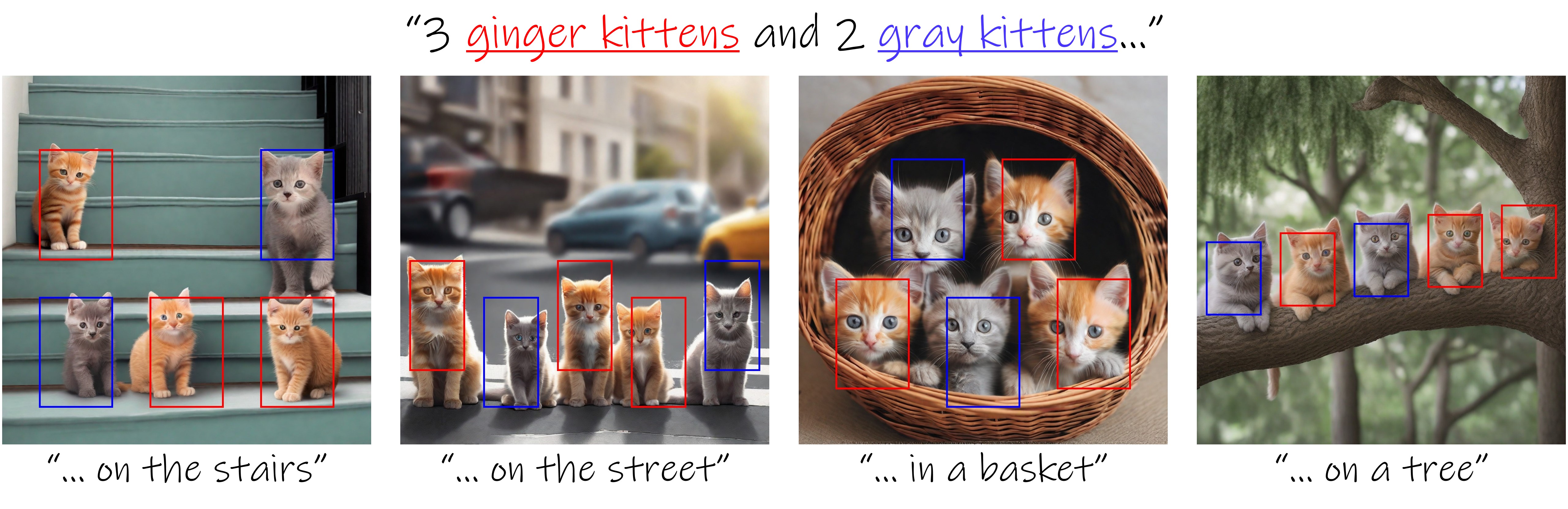
- Normalized Attention Guidance: Universal Negative Guidance for Diffusion Models - Use Negative Prompts on Guidance Distilled Models Such as Z-Image Turbochendaryen.github.io ↗Submitted 6 months ago by Even_Adder@lemmy.dbzer0.com | 0 comments
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}